
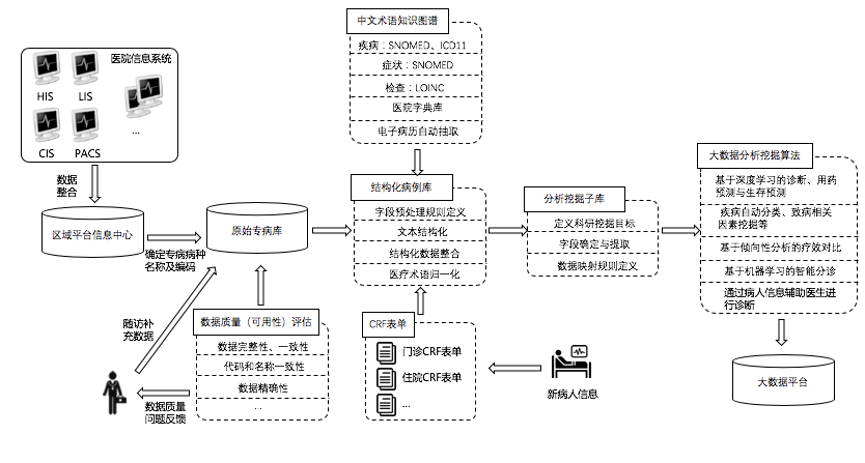
基于电子病历的临床医疗大数据挖掘整体流程
第一步,对来自不同医院的信息系统的病人数据进行数据集成,形成临床数据中心(clinical data repository, CDR)。数据来源包括医院信息系统(hospital information system, HIS)、临床信息系统(clinical information system, CIS)、实验室信息系统(Laboratory information system, LIS)、放射信息管理系统(radiology information system, RIS)、影像归档和通信系统(picture archiving and communication system, PACS)、和病案系统等信息系统。通过患者EMPI号,以时序信息整合病人的多次住院信息,同时每次住院信息中,仍存在有时序信息的检验检查结果。
第二步,由专病医生定义需要研究的病人的筛选条件,若是研究特殊疾病,则医生提供患者诊断结果中需要筛选的专病名称字段,构建面向特殊疾病的专病库,如大肠癌病例库、心衰病例库等。
第三步,由医生定义病例库字段预处理规则,并根据预处理规则结构化病例库。对于结构化的字段,需要从原始的电子病历中抽取,例如年龄与性别,对于半结构化或非结构化字段,需要使用自然语言处理等技术,例如通过实体识别技术识别出文本中的医疗实体,以构建结构化病例库。在这个过程中,因为每家医院对术语描述的不统一,对结构化病例存在挑战,例如“心功能不全”在各家医院中可能描述为“心衰”或“心力衰竭”等,所以需要构建中文术语知识图谱,以对文本中不标准的实体名称进行标准化。以上步骤构建了具有全量字段和全量样本的病例库。
第四步,根据医生定义的分析挖掘需求,从病例库中抽取需要研究的字段名称,从结构化的全量病例库中进行病例的筛选,并且进行字段的映射处理,例如新增“再入院时间”,是有下一次的入院时间减去上一次的出院时间得到的。
第五步,由医生的需求在该病例库上进行挖掘分析,得出结果反馈给医生。挖掘分析包括显著性分析,生存分析和基于人工智能的预测等。在构建原始病例库的过程中,需要对病例库的数据质量进行分析及反馈,其中包括了数据的完整性,准确性和一致性等多种医疗数据质量指标,若存在数据缺失或错误等问题,需要通过随访对数据进行补充。
此外,由于数据分析的时效性,需要实时将新病人信息存储在结构化病例库中,则需要根据结构化病例库定义CRF表单,由CRF表单将新的病人信息结构化的存储在病例库中,以构建实时结构化病例库进行分析挖掘。

